How to appear in ChatGPT search results in 2026
A specific, technical guide to getting cited by ChatGPT, what the model actually indexes, the four signals that earn citations, and a 7-day checklist you can run this week.
ChatGPT cites content that is structurally easy to extract, declarative prose, schema markup, recent dates, and topical depth. Volume doesn't help; structure does. Most teams under-publish on substance and over-publish on volume; the fix is to write fewer, sharper, well-marked-up pieces.
- ChatGPT pulls from three sources: its training corpus, live browsing via Bing, and an in-product Search index that crawls the web in near real-time.
- Citations correlate with structural clarity, not word count. A 900-word piece with FAQPage schema beats a 3,000-word piece without.
- Freshness matters: pages with explicit publishedAt and updatedAt timestamps get cited disproportionately for time-sensitive queries.
- The four signals are declarative writing, schema markup, topical depth, and recency. All four are within your control today.
- Measure with a prompt monitor across all five surfaces (ChatGPT, Perplexity, Claude, Gemini, Google AI Overviews), single-surface tracking is misleading.
How ChatGPT actually finds and cites content#
ChatGPT doesn’t have a single index. It pulls from three different sources, each with its own rules, and most of the advice on the internet conflates them.
The first source is the training corpus, the web snapshot used to pretrain the model. This is frozen at a knowledge cutoff date (typically a few months before model release) and is not refreshed continuously. Content published after the cutoff does not exist as far as the base model is concerned.
The second source is live browsing, which is powered by Bing. When ChatGPT browses, it issues a query against Bing’s search index and reads the top results. Anything blocked from Bingbot, or absent from Bing’s index, is invisible.
The third source is ChatGPT Search, a dedicated retrieval system with its own crawler called OAI-SearchBot. It crawls the open web continuously and indexes content for in-product search and citation. This is the surface most people actually see, the inline citations underneath ChatGPT’s answers, and it’s the one your site has the most leverage over.
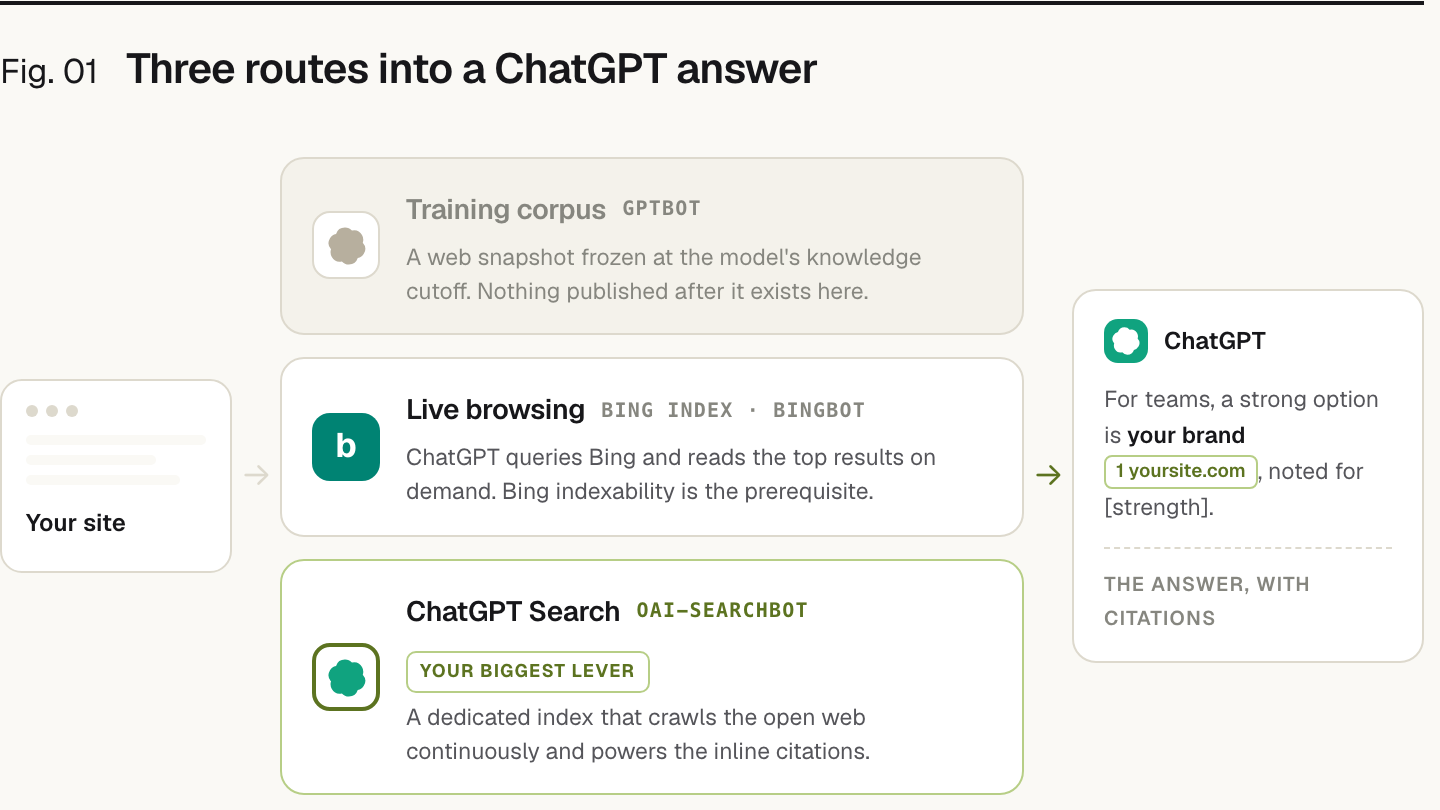
If you only do one thing after reading this guide, do this: verify that OAI-SearchBot is allowed in your robots.txt. Everything else is downstream of that.
The four signals that make content citation-ready#
Models cite content that is easy to extract, easy to verify, and recent enough to matter. The four signals below cover those three goals in practice.

Declarative, definition-led writing#
Open every section with a one-sentence answer. Then explain. Models lift the first sentence under a heading more often than any other line, by a wide margin. If your h2 is “What is GEO?”, your first sentence should be a clean definition of GEO. The rest of the section is justification.
This is the opposite of the SEO-era pattern of front-loading keywords in long meandering intros. The new pattern is: claim, then evidence. The article you’re reading is written that way on purpose.
Structured data and schema#
Schema markup tells the model what’s an answer to what. The single highest-leverage schema for citation eligibility is FAQPage, it turns a question-answer block into a structured, model-readable unit. Here’s a minimal example:
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [
{
"@type": "Question",
"name": "What is GEO?",
"acceptedAnswer": {
"@type": "Answer",
"text": "GEO is the practice of structuring content so it can be extracted, summarized, and cited by generative AI systems."
}
}
]
}Pair FAQPage with Article (for the page itself, including datePublished and dateModified) and BreadcrumbList (for hierarchical context). Don’t bother with HowTo unless your article is genuinely a step-by-step procedural.
Topical depth and authority#
Models triangulate which site to cite by looking at how many adjacent topics you’ve covered, not just the one piece they’re considering. A site with twelve good articles on AI search visibility will outrank a site with one perfect article on the same topic. Internal linking between adjacent topics compounds this. The model can see the cluster.
Authority isn’t about domain age. It’s about whether your cluster reads as written by someone who knows the subject. One canonical guide, two definition explainers, and three worked case studies is enough to be treated as a credible source on a topic.
Freshness + recency signals#
Models heavily down-weight stale content for queries with implied recency (“how to … in 2026”, “best …”, “latest …”). The fastest fix is mechanical: emit datePublished and dateModified in your Article schema and display the updated date prominently in the article header. Pages without explicit dates often get treated as undated and ignored entirely.
How each surface indexes content#
The five major AI search surfaces have meaningfully different ingestion strategies. The table below summarizes, keep it bookmarked.
| Surface | Index source | Citation style | Freshness window |
|---|---|---|---|
| ChatGPT (Search mode) | OAI-SearchBot + Bing | Inline numbered footnotes | Hours to days |
| Perplexity | PerplexityBot (own crawler) | Inline domain-named citations | Minutes to hours |
| Claude (with web) | Brave Search index | Inline links in summary | Hours to days |
| Gemini | Google Search index | Cited as “Sources” panel | Real-time (same as Google) |
| Google AI Overviews | Google Search index | Highlighted snippets at top of SERP | Real-time |
Two takeaways. First, four of the five surfaces use a third-party search index (Bing, Brave, Google), so the prerequisites are the same as classic SEO, get crawled, get indexed, be relevant. Second, only Perplexity and ChatGPT operate dedicated AI crawlers (PerplexityBot, OAI-SearchBot), and both honor robots.txt. Allowing them costs you nothing.
A 7-day checklist to get cited#
This is the ordered list. Don’t skip steps, earlier days unlock later ones.
- Day 1, Audit your robots.txt. Confirm
OAI-SearchBot,PerplexityBot, andBingbotare allowed. ~15 minutes. - Day 2, Submit sitemaps. Bing Webmaster Tools and Google Search Console. Both are free; sitemap submission accelerates discovery dramatically. ~30 minutes.
- Day 3, Add
Article+FAQPageschema to your top 5 pages. Use Schema.org’s reference and Google’s Rich Results Test to validate. ~2 hours. - Day 4, Rewrite the first paragraph of those 5 pages to be a clean, declarative answer to the page’s implied question. No throat-clearing, no keyword stuffing. ~2 hours.
- Day 5, Add
datePublishedanddateModifiedto every blog/guide page and surface the updated date visibly in the header. ~1 hour. - Day 6, Build a topical cluster. Pick your strongest topic, list every adjacent question your ICP asks, and confirm each has a dedicated URL. Plan content to fill the gaps. ~3 hours.
- Day 7, Set up a prompt monitor. Track 25–50 prompts your buyers actually type into ChatGPT/Perplexity/Claude/Gemini/AIO. Without this, you can’t measure whether any of the above is working. ~1 hour, then ongoing.
Five common mistakes#
These are the patterns I see in nearly every Visibly audit. None of them are exotic; all of them are fixable.
- Burying the answer. The query is “what is X” and the page opens with three paragraphs of company-positioning before getting to the definition. Move the answer to the first line.
- Skipping schema. Teams will write a 2,500-word guide and ship it without
ArticleorFAQPageschema. The model can’t tell which paragraph is the answer. - Stale dates. “Updated 2023” on a 2026 query is a citation killer. If you haven’t actually updated, schedule a real refresh and emit
dateModified. - Volume over substance. Forty thin posts beat by five strong ones. Models cite the strong ones; thin posts dilute your cluster authority.
- Subdomain or subfolder content mills. Hosting AI-generated content on
content.yoursite.com/articles/is transparent to both Google and AI systems. Publish into your main site or don’t publish at all.
A glossary for the rest of this guide#
The terms below show up across this article and the rest of the AI-visibility canon. If you’ve been nodding along but unsure of one, here’s the precise meaning we use.
- GEO
- Generative Engine Optimization. The practice of structuring content so it can be extracted and cited by generative AI systems. Distinct from SEO but overlapping.
- AI Overviews
- Google’s in-SERP generative summaries that appear above traditional blue links for certain queries. Powered by Gemini, sourced from Google’s existing search index.
- Browse mode
- The capability of an LLM to fetch live web pages mid-conversation, typically via a third-party search API. ChatGPT browses via Bing; Claude via Brave.
- Citation density
- The number of distinct sources cited in a single AI-generated answer. Higher density means more inventory positions per query, and more opportunity for your site.
- Declarative prose
- Writing that opens with a claim, then supports it. The opposite of inverted-pyramid throat-clearing. Models extract declarative leads disproportionately often.
How to measure whether it’s working#
Two metrics matter. The first is your share of citations on the prompts your buyers actually issue, not generic head terms, but the long-tail, intent-rich queries that drive consideration. The second is trend over time: are you appearing in more answers, more often, across more surfaces?
Neither metric is visible in Google Search Console. You measure them by running a prompt monitor, software that issues the same prompts against ChatGPT, Perplexity, Claude, Gemini, and Google AI Overviews on a daily or weekly schedule and tracks whether your domain is cited.
Visibly does this from $49/month across all five surfaces. If you want the diagnosis first, the free AI-visibility audit covers your top 25 prompts plus a full opportunity scan. Either way, the rule stands: you can’t fix what you don’t measure.
The bar is lower than it looks. Most teams in most categories have not done any of the work above. The first team in a category that does is the team that gets cited, and stays cited, for the next 12 to 24 months.
- Does ChatGPT use Bing search results?
- Can I submit my website to ChatGPT directly?
- How often does ChatGPT's training data update?
- What is GEO (Generative Engine Optimization)?
- Why does ChatGPT cite some sites and not others?
Frequently asked questions
Does ChatGPT use Bing search results?
Yes, ChatGPT's live browsing feature is powered by Bing's search index. When ChatGPT 'browses the web', it issues queries against Bing and reads the top results. This means Bing indexability is a prerequisite for live-browse citation. Submit your sitemap to Bing Webmaster Tools and verify your site is crawlable by Bingbot.
How often does ChatGPT's training data update?
Training cutoffs vary by model and ship at irregular intervals (typically every few months for newer models). For time-sensitive topics, never rely on the training corpus, your goal is to be picked up by live browsing and by the dedicated ChatGPT Search index, both of which refresh continuously. Publish dates and updated timestamps signal recency to those systems.
What is GEO (Generative Engine Optimization)?
GEO is the practice of structuring content so it can be extracted, summarized, and cited by generative AI systems. It overlaps with traditional SEO but emphasizes different signals: schema markup (FAQPage, Article, HowTo), declarative answer-first prose, definition-style writing, and freshness. GEO assumes the reader is a model, not just a human.
Can I submit my website to ChatGPT directly?
No, there is no submission form. The closest you can get is making sure (a) Bingbot can crawl your site, (b) you publish a sitemap, (c) your robots.txt does not block OAI-SearchBot (ChatGPT's own crawler), and (d) your content is structured to be extractable. ChatGPT discovers content through the same channels Google does, plus its own dedicated crawler.
Why does ChatGPT cite some sites and not others?
Three reasons, in order: topical relevance to the query, structural extractability of the answer, and source authority. A small site with a definition-led paragraph and FAQPage schema can outrank a large site that buries the answer in marketing copy. The model is optimizing for 'cite this and the user will be satisfied', not for domain authority alone.
Should I block AI crawlers from my site?
If you want to be cited, no. The two relevant crawlers are GPTBot (used for training) and OAI-SearchBot (used by ChatGPT Search to index in real-time). Blocking GPTBot opts you out of future training data but does not affect live citation. Blocking OAI-SearchBot opts you out of being cited by ChatGPT entirely. Most teams should allow OAI-SearchBot and decide on GPTBot based on whether they want their content used for training.